Ein praxisorientierter Leitfaden für Entscheider und Entwickler im deutschen Mittelstand.
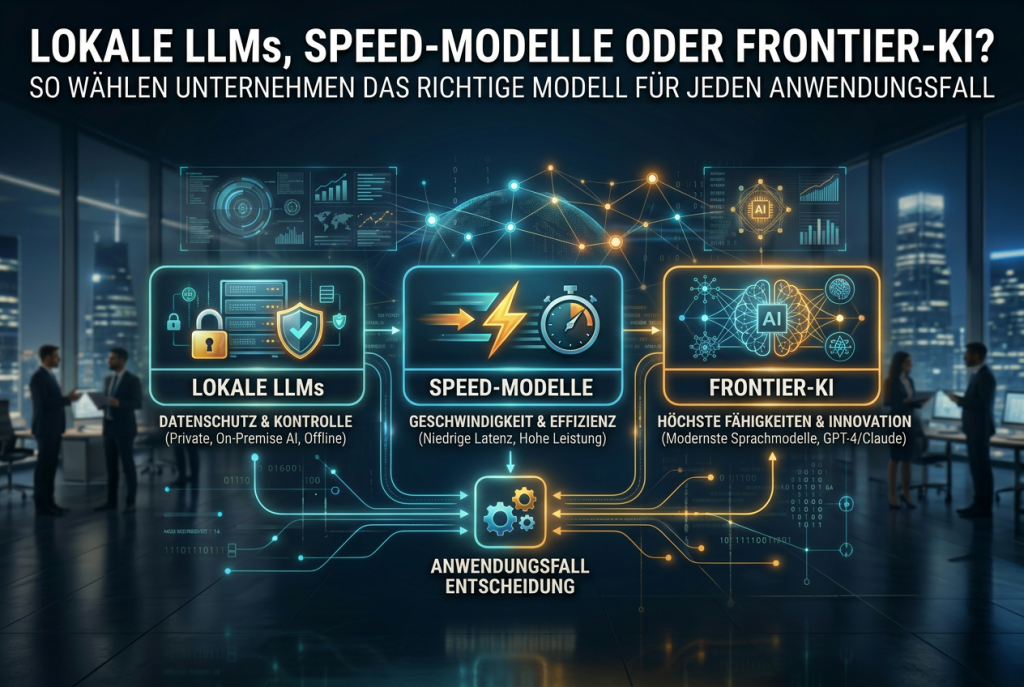
Die KI-Landschaft 2026 stellt uns vor eine neue Herausforderung: Es gibt nicht mehr zu wenig Auswahl, sondern zu viel. Lokale Open-Source-Modelle wie Llama 3.3 oder Qwen 3 laufen auf handelsüblicher Hardware. Speed-optimierte Modelle wie Mercury 2 von Inception Labs liefern über 1.000 Tokens pro Sekunde. Und Frontier-Modelle wie Claude Opus 4.6 oder GPT-5.4 setzen neue Massstäbe bei komplexem Reasoning, Coding und agentengestützten Workflows.
Die Frage ist nicht mehr: „Welches Modell ist das beste?“ Sondern: „Welches Modell ist das richtige für welche Aufgabe, und wie kombiniere ich sie intelligent?“
Dieser Artikel gibt Ihnen eine Entscheidungsgrundlage.
1. Lokale LLMs: Datensouveränität und Kostenkontrolle
Was sie sind: Open-Source- oder Open-Weight-Modelle, die auf eigener Hardware laufen. Kein API-Call, keine Cloud, keine Tokenkosten.
Die wichtigsten Vertreter 2026:
Llama 3.3 (Meta, 8B/70B) gilt als das vielseitigste Open-Weight-Modell mit dem grössten Community-Ökosystem. Qwen 3 (Alibaba, 7B bis 235B) dominiert bei Code-Generierung und mehrsprachigen Aufgaben. Mistral Small 3 (Mistral AI, 7B) bietet die höchste Inferenzgeschwindigkeit auf Consumer-Hardware. Phi-4-mini (Microsoft, 3.8B) ist die einzige realistische Option für Geräte mit nur 8 GB RAM.
Wann lokale Modelle die richtige Wahl sind:
Der stärkste Treiber ist Datensouveränität. Wer proprietäre Codebases, Kundendaten oder regulierte Informationen verarbeitet, kann diese oft nicht an Cloud-APIs senden. In der deutschen Industrie, besonders im Automotive- und Halbleiterbereich, ist das ein K.O.-Kriterium.
Der zweite Treiber sind Kosten. Bei hohem Volumen, etwa in RAG-Pipelines, automatisierter Code-Review oder internen Chatbots, summieren sich API-Kosten schnell. Ein lokales 8B-Modell auf einer RTX 4090 verarbeitet tausende Anfragen pro Tag ohne laufende Kosten.
Der dritte Vorteil: Offline-Fähigkeit. Produktionsumgebungen in der Industrie haben nicht immer stabile Internetverbindungen. Ein lokales Modell funktioniert auch in der Werkshalle.
Was sie nicht können:
Komplexes Multi-Step-Reasoning, anspruchsvolle agentengestützte Workflows und kreative Aufgaben auf Frontier-Niveau liegen ausserhalb der Reichweite der meisten lokalen Modelle. Ein quantisiertes 7B-Modell erreicht etwa 80-90% der Qualität von GPT-5.2 bei Standardaufgaben, aber bei wirklich schwierigen Problemen ist der Abstand spürbar.
Praxistipp: Beginnen Sie mit Llama 3.3 8B via Ollama. Installation dauert drei Befehle, und die meisten Alltagsaufgaben, von Code-Completion über Zusammenfassungen bis hin zu E-Mail-Entwürfen, erledigt es zuverlässig.
2. Speed-optimierte Modelle: Wenn Latenz über den Produktionseinsatz entscheidet
Was sie sind: Cloud-basierte Modelle, die auf maximalen Durchsatz und minimale Latenz optimiert sind. Sie liefern brauchbare Qualität bei einem Bruchteil der Kosten und Wartezeit von Frontier-Modellen.
Der Gamechanger 2026: Mercury 2
Inception Labs hat mit Mercury 2 einen fundamental anderen Ansatz gewählt. Statt Tokens sequentiell zu generieren (wie alle grossen Modelle von OpenAI, Anthropic und Google), nutzt Mercury 2 einen Diffusion-Ansatz: Das Modell beginnt mit einer groben Skizze der gesamten Antwort und verfeinert sie iterativ, wobei viele Tokens parallel verarbeitet werden.
Das Ergebnis: Über 1.000 Tokens pro Sekunde Durchsatz auf NVIDIA Blackwell GPUs. Das ist fünf- bis zehnmal schneller als vergleichbare Speed-Modelle wie Claude 4.5 Haiku oder GPT-5.2 Mini, bei vergleichbarer Qualität. Die Kosten liegen bei 0,25 USD pro Million Input-Tokens und 0,75 USD pro Million Output-Tokens.
Wann Speed-Modelle die richtige Wahl sind:
Der wichtigste Anwendungsfall sind Agenten-Loops. Wenn ein KI-Agent in einer Automatisierungspipeline zehn, zwanzig oder hundert aufeinanderfolgende Aufrufe macht, multipliziert sich die Latenz jedes einzelnen Calls. Ein Modell, das pro Aufruf 200ms statt 2 Sekunden braucht, macht den Unterschied zwischen einem nutzbaren Produkt und einem Prototypen.
Ebenso relevant: Echtzeit-Coding-Assistenz (Autocomplete, Inline-Suggestions), RAG-Pipelines mit mehrstufigem Retrieval und Reranking, sowie jede Anwendung, in der die User Experience direkt von der Antwortzeit abhängt.
Was sie nicht können:
Mercury 2 erreicht die Qualität von Haiku- und Mini-Klasse-Modellen, nicht die von Opus oder GPT-5.4. Für komplexe Analysen, kreative Arbeit oder Aufgaben, die tiefes Reasoning erfordern, sind Frontier-Modelle weiterhin überlegen.
Praxistipp: Mercury 2 ist OpenAI-API-kompatibel. Sie können es in bestehende Infrastruktur als Drop-in-Replacement integrieren, ohne Code umzuschreiben. Ideal für Teams, die bereits mit OpenAI-kompatiblen Tools arbeiten.
3. Frontier-Modelle: Wenn Qualität und Reasoning-Tiefe zählen
Was sie sind: Die leistungsfähigsten kommerziellen Modelle, die den Stand der Technik bei Reasoning, Coding, Analyse und agentengestützten Workflows definieren.
Die zwei Schwergewichte 2026:
Claude Opus 4.6 (Anthropic) ist das aktuell stärkste Modell für komplexe professionelle Arbeit. Mit einem 1-Million-Token-Kontextfenster, 128K Max-Output und Agent-Teams (mehrere Agenten, die parallel an Teilaufgaben arbeiten) setzt es neue Massstäbe. Es dominiert Benchmarks in den Bereichen Coding, Legal Reasoning, Financial Analysis und Cybersecurity. Preislich liegt es bei 5 USD pro Million Input-Tokens und 25 USD pro Million Output-Tokens.
GPT-5.4 (OpenAI) ist das erste General-Purpose-Modell von OpenAI mit nativen Computer-Use-Fähigkeiten. Es unterstützt bis zu 1 Million Tokens Kontext, bringt die Coding-Fähigkeiten von GPT-5.3-Codex mit und bietet Tool Search, das Agenten hilft, die richtigen Werkzeuge effizienter zu finden. Verfügbar in ChatGPT, Codex und via API.
Wann Frontier-Modelle die richtige Wahl sind:
Komplexe, mehrstufige Aufgaben, die Planung, Ausführung und Überprüfung erfordern. Ein Bug in einer 50.000-Zeilen-Codebase finden und beheben. Hunderte Verträge analysieren und Risiken identifizieren. Eine Due-Diligence durchführen, die Finanzdaten, Marktanalysen und regulatorische Informationen synthetisiert.
Opus 4.6 hat beispielsweise in einem Test autonom 13 Issues geschlossen und 12 Issues den richtigen Teammitgliedern zugewiesen, in einer Organisation mit rund 50 Personen und 6 Repositories. Es wusste, wann es an einen Menschen eskalieren musste. Das ist ein qualitativ anderes Level als das, was Speed- oder lokale Modelle leisten.
Was sie kosten:
Frontier-Modelle sind die teuerste Option. Bei hohem Volumen können die Kosten signifikant werden. Opus 4.6 bietet bis zu 90% Einsparungen durch Prompt Caching und 50% durch Batch Processing. Trotzdem ist die sorgfältige Wahl, welche Aufgaben tatsächlich Frontier-Qualität brauchen, wirtschaftlich entscheidend.
Praxistipp: Nutzen Sie Frontier-Modelle nicht für alles. Setzen Sie sie gezielt ein: für die schwierigsten 10-20% Ihrer Aufgaben, bei denen Qualität und Zuverlässigkeit den Preisunterschied rechtfertigen.
4. Die intelligente Kombination: Ein Modell-Stack für die Praxis
Die erfolgreichsten Teams 2026 nutzen nicht ein Modell, sondern einen Stack. Das Prinzip:
Tier 1: Lokale Modelle für Volumen und Privatsphäre. Interne Chatbots, Code-Completion, Datenextraktion, Klassifikation. Llama 3.3 8B oder Qwen 3 7B via Ollama. Keine laufenden Kosten, volle Datenkontrolle.
Tier 2: Speed-Modelle für latenzempfindliche Produktion. Agenten-Loops, Echtzeit-Suche, Autocomplete, High-Volume-Pipelines. Mercury 2 oder vergleichbare Speed-optimierte APIs. Niedrige Kosten, hoher Durchsatz.
Tier 3: Frontier-Modelle für komplexe Wissensarbeit. Strategische Analysen, komplexe Codebase-Refactorings, Multi-Source-Research, agentengestützte Projektarbeit. Claude Opus 4.6 oder GPT-5.4. Höchste Qualität, höchste Kosten.
Die Kunst liegt im Routing: Ein intelligentes System entscheidet automatisch, welche Anfrage welches Modell braucht. OpenAI macht das bereits intern bei Codex, wo GPT-5.4 die Planung übernimmt und GPT-5.4 mini als günstigerer Subagent die einfacheren Teilaufgaben ausführt.
5. Entscheidungsmatrix: Welches Modell wann?
Datensouveränität ist Pflicht? Lokales Modell. Kein Kompromiss.
Latenz unter 500ms pro Aufruf nötig? Speed-Modell (Mercury 2) oder lokales Modell.
Komplexes Reasoning über grosse Datenmengen? Frontier-Modell (Opus 4.6 oder GPT-5.4).
Hunderte gleichartige Aufgaben pro Tag? Lokales Modell für Standardaufgaben, Speed-Modell für mittlere Komplexität.
Einmalige, hochkomplexe Analyse? Frontier-Modell. Die Kosten pro Einzelaufgabe sind vernachlässigbar, die Qualitätsdifferenz nicht.
Mehrsprachige Anforderungen (DACH + international)? Qwen 3 lokal oder Frontier-Modell, je nach Qualitätsanspruch.
Fazit: Es gibt kein „bestes“ Modell. Es gibt die beste Kombination.
Die LLM-Landschaft 2026 ist kein Winner-takes-all-Markt. Lokale Modelle, Speed-Modelle und Frontier-Modelle sind keine Konkurrenten, sondern Schichten eines intelligenten Technologie-Stacks.
Für den deutschen Mittelstand bedeutet das konkret: Beginnen Sie mit einem lokalen Modell für Ihre häufigsten Standardaufgaben. Evaluieren Sie Speed-Modelle wie Mercury 2 für Ihre latenzempfindlichen Produktionsprozesse. Und reservieren Sie Frontier-Modelle wie Opus 4.6 oder GPT-5.4 für die Aufgaben, bei denen Qualität wirklich zählt.
Wer alle drei Ebenen versteht und intelligent kombiniert, hat 2026 einen echten Wettbewerbsvorteil.
Was ist Ihre Erfahrung? Nutzen Sie bereits einen Multi-Modell-Ansatz, oder setzen Sie noch auf ein einzelnes Modell für alles? Ich freue mich auf den Austausch.
Über den Autor: Holger Gerlach ist VP Business Development bei Gefasoft Engineering in Regensburg und begleitet seit über 30 Jahren Digitalisierungsprojekte. Er schreibt regelmässig über KI, Industrie 4.0/5.0 und pragmatische Technologiestrategien.